|
|
You are here: Wiki_Virgo_LSC>InformationSystem Web>Basic_Cluster_Management (06 Jun 2019, Salconi)Edit Attach
A) Accesso ai cluster via web
In linea di massima si puo' accedere ad ogni macchina del cluster tramite interfaccia web:https://st0x.virgo.infn.it/2224dove st0x e' una macchina nel range st03-st06 La login di accesso e' "hacluster", la password e' quella dello storage.
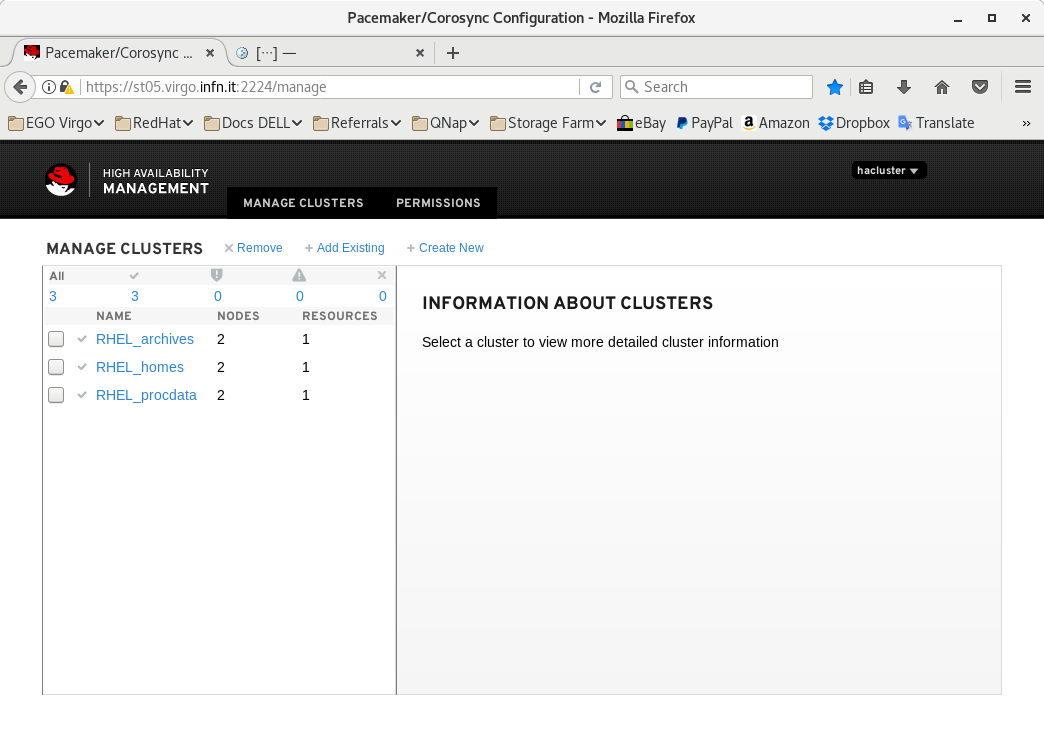 Sono visibili dalla prima schermata i gruppi di cluster (archivi, homes e procdata), le macchine attive che ne fanno parte e le macro risorse.
Si seleziona quindi il cluster con cui si vuole operare (es. homes) e la macchina di cui si vuole conoscere lo stato o su cui si vuole operare (es. st04):
Sono visibili dalla prima schermata i gruppi di cluster (archivi, homes e procdata), le macchine attive che ne fanno parte e le macro risorse.
Si seleziona quindi il cluster con cui si vuole operare (es. homes) e la macchina di cui si vuole conoscere lo stato o su cui si vuole operare (es. st04):
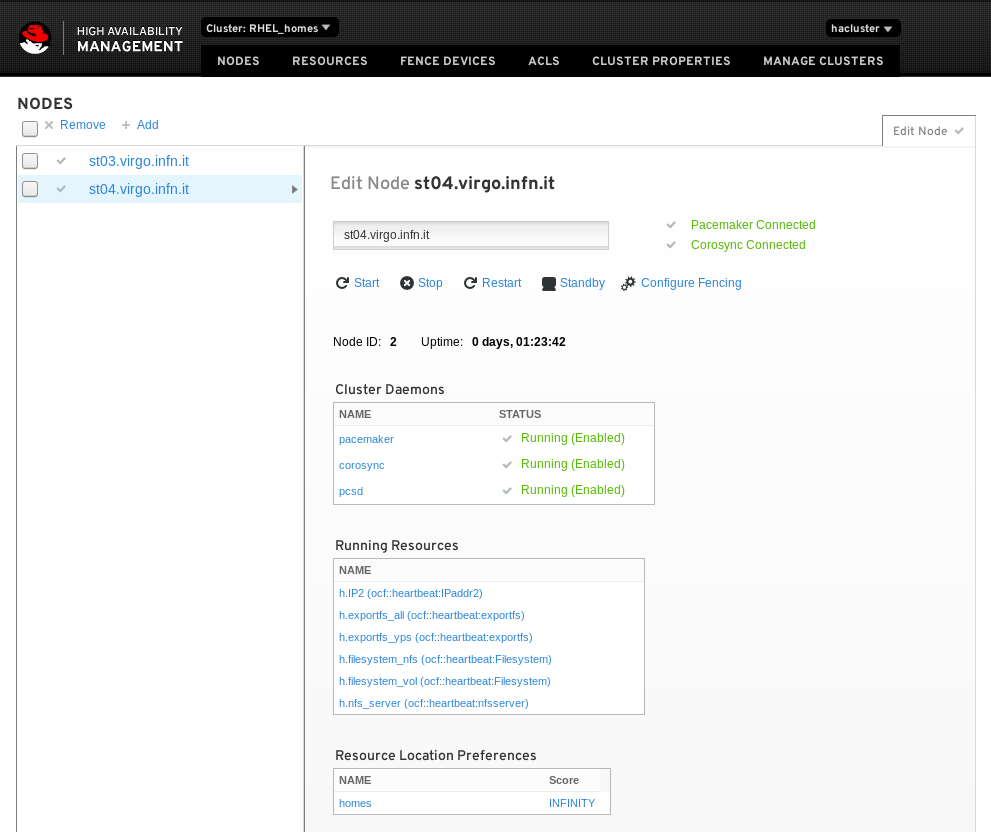 Si possono adesso verificare lo stato delle risorse (se attive e dove) e lanciare dei comandi al singolo host componente il cluster: start e stop (servizio cluster), restart (reboot), standby (sospensione serivizio e risorse) o configurare il fencing.
Selezionando in alto "resources" abbiamo il dettaglio di ogni singole risorsa:
Si possono adesso verificare lo stato delle risorse (se attive e dove) e lanciare dei comandi al singolo host componente il cluster: start e stop (servizio cluster), restart (reboot), standby (sospensione serivizio e risorse) o configurare il fencing.
Selezionando in alto "resources" abbiamo il dettaglio di ogni singole risorsa:
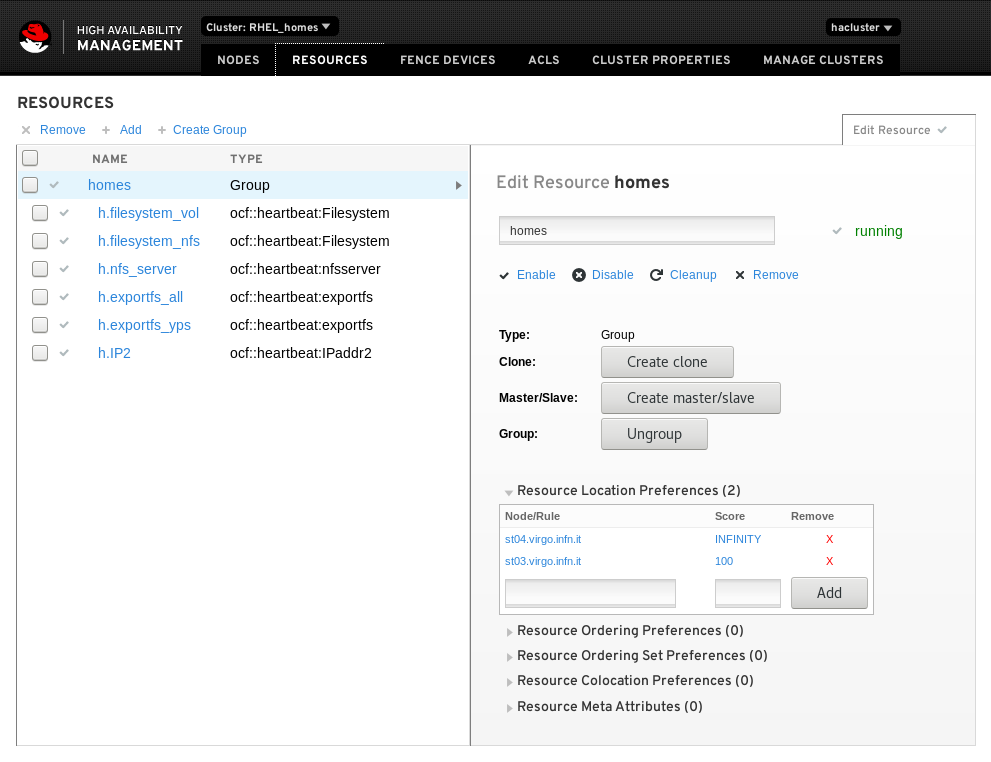 Si puo' notare come la macro risorsa (homes) comprenda tutte le altre. Questa risulta correttamente in funzione quando e' di colore blu.
Colore rosso indica un errore nella risorsa mentre arancio indica una risorsa in standby.
La macro risorsa divene blu solo e soltanto se tutte le risorse che la compongono sono blu, ovvero avviare con successo.
Nel caso una risorsa sia in errore o abbia un problema (indicato da un triangolo giallo) si puo' provare a far rileggere/resettare la risorsa con il comando "cleanup".
Dato che le nostre risorse sono tutte sequenzializzate, di solito non e' il caso di interrompere (enable/disable) o meno che mai cancellare (cleanup) una risorsa intermedia perche' questo causerebbe il fallimento dll'intero gruppo.
Le risorse hanno un nome che deriva da dal gruppo e tipo di risorsa usata: per esempio h.filesystem_vol identifica una risorsa del gruppo homes, di tipo filesystem, specificamente il "vol" xfs contenente le homes.
Cliccando su di una risorsa (esempio h.filesystem_vol) si vedono le caratterstiche evidenziate:
Si puo' notare come la macro risorsa (homes) comprenda tutte le altre. Questa risulta correttamente in funzione quando e' di colore blu.
Colore rosso indica un errore nella risorsa mentre arancio indica una risorsa in standby.
La macro risorsa divene blu solo e soltanto se tutte le risorse che la compongono sono blu, ovvero avviare con successo.
Nel caso una risorsa sia in errore o abbia un problema (indicato da un triangolo giallo) si puo' provare a far rileggere/resettare la risorsa con il comando "cleanup".
Dato che le nostre risorse sono tutte sequenzializzate, di solito non e' il caso di interrompere (enable/disable) o meno che mai cancellare (cleanup) una risorsa intermedia perche' questo causerebbe il fallimento dll'intero gruppo.
Le risorse hanno un nome che deriva da dal gruppo e tipo di risorsa usata: per esempio h.filesystem_vol identifica una risorsa del gruppo homes, di tipo filesystem, specificamente il "vol" xfs contenente le homes.
Cliccando su di una risorsa (esempio h.filesystem_vol) si vedono le caratterstiche evidenziate:
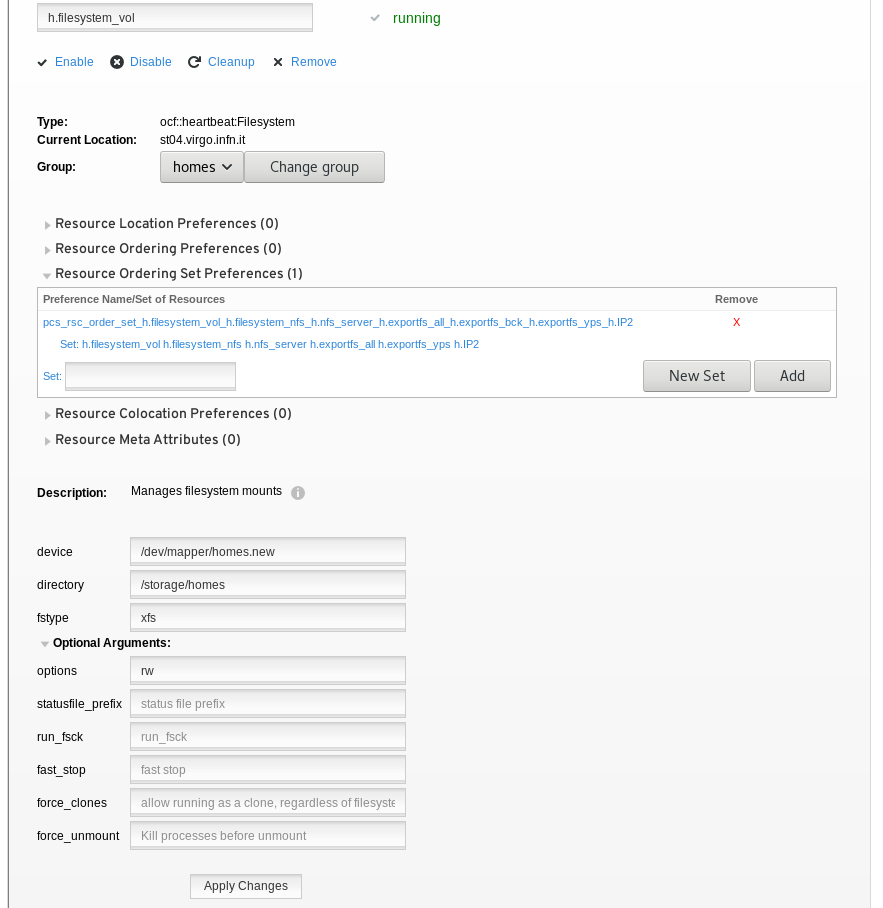 Si nota la sequenza di avvio specificata per il server NFS delle homes, ovvero:
- il file system delle homes;
- il file system dei lock;
- l'NFS server vero e proprio;
- l'IP di servizio;
- i vari exportfs (per tutti, per yp server, etc...);
Si nota la sequenza di avvio specificata per il server NFS delle homes, ovvero:
- il file system delle homes;
- il file system dei lock;
- l'NFS server vero e proprio;
- l'IP di servizio;
- i vari exportfs (per tutti, per yp server, etc...);
A.1) In sostanza, cosa su puo' fare via web in caso di emergenza:
- vedere lo stato del cluster, delle singole macchine e delle risorse associate ed individuare la possibile causa di un problema; - mettere in blocco (enable/disable) il cluster di una specifica macchina per metterla in manutenzione, spostando in automatico le risorse sull'altra macchina; - effettuare un reboot di una macchina (restart) spostando le risorse sull'altra macchina; - ricaricare un gruppo di risorse o una risorsa in errore (cleanup); Le altre funzioni sono da intendersi per un uso solo dedicato all'installazione e la configurazione del cluster o di nuove risorse.B) Accesso ai cluster via CLI
E' sufficente accedere come "root" ad una qualsiasi delle macchine st0x.virgo.infn.it che compongono il cluster, la password resta quella dello storage. Per esmpio:# ssh root@st05.virgo.infn.itper verificare lo stato del cluster e' sufficnete digitare:
# pcs statuse si ottiene la lista delle macchine e delle risorse che lo compongono ed il loro status: [root@st05 ~]# pcs status
Cluster name: RHEL_procdata
Last updated: Thu Apr 27 15:31:29 2017 Last change: Fri Mar 24 10:01:36 2017 by root via cibadmin on st05.virgo.infn.it
Stack: corosync
Current DC: st05.virgo.infn.it (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
2 nodes and 10 resources configured
Online: [ st05.virgo.infn.it st06.virgo.infn.it ]
Full list of resources:
idrac_st05 (stonith:fence_idrac): Started st05.virgo.infn.it
idrac_st06 (stonith:fence_idrac): Started st06.virgo.infn.it
Resource Group: procdata
p.filesystem_vol (ocf::heartbeat:Filesystem): Started st05.virgo.infn.it
p.filesystem_nfs (ocf::heartbeat:Filesystem): Started st05.virgo.infn.it
p.nfs_server (ocf::heartbeat:nfsserver): Started st05.virgo.infn.it
p.IP2 (ocf::heartbeat:IPaddr2): Started st05.virgo.infn.it
p.exportfs_all (ocf::heartbeat:exportfs): Started st05.virgo.infn.it
p.exportfs_procdata (ocf::heartbeat:exportfs): Started st05.virgo.infn.it
p.exportfs_procdata_w3 (ocf::heartbeat:exportfs): Started st05.virgo.infn.it
p.filesystem_cbc (ocf::heartbeat:Filesystem): Started st05.virgo.infn.it
PCSD Status:
st05.virgo.infn.it: Online
st06.virgo.infn.it: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
con in evidenza lo stato delle macchine e delle risorse e la loro assegnazione. Con il comando "pcs" e' possibile fare qualunque operazione all'interno del cluster, le operazioni disponibili sono superiori a quelle che si possono effettuare con l'interfaccia grafica. Digitando pcs seguito da <tab> e' possibile ottenere la lista iniziale dei comandi disponibili:
# pcs →TAB[root@st05 ~]# pcs
acl cluster config constraint property resource status stonith A seconda di dove si voglia operare o cosa fare. Le scelte sono "nested", come il <tab>, se volessimo conoscere le opzioni dei comandi per operare sulle risorse abbiamo:
# pcs resource →TAB[root@st05 ~]# pcs resource
agents clear debug-demote debug-start delete enable list meta providers show ungroup
ban clone debug-monitor debug-stop describe failcount manage move relocate standards unmanage
cleanup create debug-promote defaults disable group master op restart unclone update Nel caso volessimo conoscere l'ordine di caricamento delle risorse, si digita:
# pcs constraint order[root@st05 ~]# pcs constraint order
Ordering Constraints:
Resource Sets:
set p.filesystem_vol p.filesystem_cbc p.filesystem_nfs p.nfs_server p.IP2 p.exportfs_all p.exportfs_procdata p.exportfs_procdata_w3 Nella fase di configurazione o dopo aver aggiunto una risorsa, per inserirla nellordine di caricamento si annulla il precedente ordine e lo si crea di nuovo:
# pcs constraint order show
# pcs constraint order clear
# pcs constraint order set resource_1 resource_2 … resource_NCome si vede e' piuttosto complicato navigare all'interno della CLI, c'e' sempre rischio di causare danno, ma e' anche il sistema piu' veloce e sicuro per accedere ad un cluster.


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
cluster_img_1.png | manage | 67 K | 06 Jun 2019 - 08:24 | Main.Salconi | |
| |
cluster_img_2.png | manage | 72 K | 06 Jun 2019 - 08:24 | Main.Salconi | |
| |
cluster_img_3.png | manage | 90 K | 06 Jun 2019 - 08:24 | Main.Salconi | |
| |
cluster_img_4.png | manage | 74 K | 06 Jun 2019 - 08:24 | Main.Salconi |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r1 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r1 - 06 Jun 2019, Salconi
- Toolbox
-
 Create New Topic
Create New Topic
-
 Index
Index
-
 Search
Search
-
 Changes
Changes
-
 Notifications
Notifications
-
 RSS Feed
RSS Feed
-
 Statistics
Statistics
-
 Preferences
Preferences
Ideas, requests, problems regarding Wiki_Virgo_LSC? Send feedback